제작 배경
- 평소 교회 갈 때는 성경이 무겁다는 핑계로 잘 들고 다니지 않게 되다 보니 간단한 성경 조회 사이트를 만들어서 휴대폰으로 볼 수 있게 만들어야겠다는 결심을 하게 되었다. 사실 성경을 볼 수 있는 무료 앱도 있지만 상단에 비치되는 배너 광고가 보고 싶지 않았다.
얼핏 생각해도 금방 만들 수 있을 것 같아서 시작하게 되었고, 예상대로 금방 만들었다.
먼저 제작 과정은 아래와 같았다.
- 성경 내용 수집, 조회 방식을 고려한 데이터 형식 선정
- 성경 조회 서비스 개발(백엔드)
- 성경 조회 및 결과 확인을 위한 정적 html 제작 (프론트)
위 제작 과정에 따라 차근차근 살펴보도록 하겠다.
성경 내용 수집
- 사이트 선정 (http://www.holybible.or.kr/)
성경 수집을 위해 구글, 네이버 서칭을 시도했다. 이미 제작된 텍스트 파일이 있다면 그것을 쓰고, 없다면 크롤링할 계획이었다. 그래서 세 가지 경우에 접근할 수 있었다.- txt파일로 성경을 이미 저장해 둔 파일이 있었다. 하지만 오타가 많아 신뢰성이 다소 떨어졌다.
- 성경 읽기 서비스를 제공하는 사이트는 여럿 있었다. 그 중 '대한성서공회'와 '다국어성경' 사이트에 대하여 크롤링을 시도했는데 결론적으로 '다국어성경' 사이트에서 자료를 수집했다.
이슈 사항
참고로 '대한성서공회' 사이트는 수집을 위한 request 결과로 아래와 같은 에러가 발생했다.
[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (ssl.c:1131)
위 에러는 SSL/TLS 인증서에 문제가 있다는 것을 의미하는데, 해당 사이트의 인증서를 확인해 본 결과 Thawte TLS RSA CA G1라고 하는 중간(체인) 인증서를 사용하는 것이 문제가 되는 것 같았다.
크롤링할 때 주로 사용하는 python requests 패키지에서는 certifi라는 라이브러리를 적용하여 https 사이트에서 보내준 인증서에 대한 검증을 진행하는데 해당 라이브러리에 등록되지 않은 인증서여서 검증을 못하는 것으로 추측했다.
루트 인증서는 DigiCert Global Root G2로 certifi 라이브러리에 등록된 것을 확인했기에 수동으로 중간 인증서를 지정해주면 문제가 해결될 것이라 예상했다. 하지만 해당 인증서를 직접 다운받아 경로 지정도 해봤지만 여전히 문제는 해결되지 않았다. 추후 파이썬 ssl과 socket 라이브러리를 활용한 접근을 시도해서 문제를 해결해 볼 예정이다.
크롤링 방식 선정
다시 본론으로 돌아와 '다국어성경'이라는 사이트를 대상으로 크롤링을 진행했다.
크롤링은 항상 두 가지 방법으로 접근한다.
- html을 파싱 후 태그에 접근해서 정보를 획득한다.
- 엔드포인트로 직접 접근하여 페이로드를 응답 받아 정보를 획득한다.
해당 사이트에서는 1번 방법으로 접근했다. 아래 url을 보자
http://www.holybible.or.kr/B_GAE/cgi/bibleftxt.php?VR={vr}&VL={vl}&CN={cn}&CV=99
쿼리스트링에서 VR, VL, CN, CV 등이 성경 내용 조회에 필요한 조건이다. VL은 '창세기', '출애굽기'와 같은 책 제목에 해당하고 CN은 '장'에 해당한다. 그러므로 위 값을 변경하면서 성경 전체를 훑어보며 내용을 수집하면 된다.
사실 나는 위 방법보다는 2번을 더 선호한다. 왜냐하면 1번은 '창세기 1장' 부터 '요한계시록 22장'까지 일일이 다 조회해야 하는데 매번 html이 렌더링 되는 시간을 기다려야 하기 때문이다. 즉 오래걸린다. 2번의 경우 데이터 조회만을 위한 엔드포인트가 크롬 네트워크에 노출이 되는 경우에만 접근이 가능하지만 제공만 된다면 html 렌더링 과정을 피할 수 있어 더 빠르다. 하지만 '성경'이라는 데이터 특성 상 정적 데이터, 즉 웬만해서는 변하지 않는 정보에 해당하므로 데이터 조회 및 html 렌더링을 한 번에 수행하도록 구현된 것으로 보인다. 그렇다면 2번 방식의 접근은 불가하다.
자료 저장 형식 설정
성경 내용이 사실상 그리 많은 데이터량을 차지하는 것은 아니다. js파일에 해당 텍스트를 다 담은 용량이 25mb 정도 밖에 되지 않았다. 게다가 정적 데이터에 해당하므로 변동의 여지도 없다고 봐야 한다. 그렇다면 성경을 통째로 로컬에 저장한 뒤 key값으로 빠르게 접근하여 조회하도록 하는게 가장 간단하고 빠른 방법이라 생각했다. 굳이 데이터베이스를 고려할 필요가 없다고 판단했다.
보관 형식은 딕셔너리(key: value)와 리스트 자료형으로 아래와 같이 저장하기로 결정했다.
{
'개역개정': {
'창': {
1: [
'1 태초에 하나님이.....'
]
2: [...]
},
'출': {
...
}
},
'개역한글': {...}
}조회 시 번역본 선택(개역개정, NIV, KJV 등)과 책이름과 '장'을 조회하고 '절'의 경우는 따로 조회하지 않고 한꺼번에 가져오는 것을 기준 로 데이터를 수집했다.
크롤링 코드 보기
크롤링은 주로 주피터노트북에서 작성한다. 그 이유는 셀 단위로 코드를 구분하여 실행할 수 있어 중간 단계를 체크하기에 용이하다는 점과 특정 셀에서 오류가 발생하더라도 그 이전까지 적용된 변수의 변경사항이 보존되기 때문이다. 일종의 대화형 환경을 제공한다고 볼 수 있다.
# jypyter notebook으로 실행
import requests
from tqdm import tqdm_notebook
from bs4 import BeautifulSoup
# INIT
# VR = GAE(개역개정), VL = 책, CN = 장, CV = 동시출력(NIV, 새번역 등등) 디폴트 99
VR_DICT = {
'GAE': '개역개정',
'RHV': '개역한글',
'SAENEW': '새번역',
'NIV': 'NIV',
'KJV': 'KJV',
}
# 성경 저장소
bible = {}
for vr in tqdm_notebook(VR_DICT.keys()):
bible[vr] = {} # vr 키 생성
# initial 변수는 ['창', '출', '레', ....'계'] 를 보관하고 있는 책 이름 변수이다.
# 성경 이름을 iterate
for idx, name in tqdm_notebook(enumerate(initial), total=len(initial), leave=False):
vl = idx + 1
# 성경 name key db 생성
bible[vr][name] = {}
# 장을 iterate
cn = 1
while True:
url = f'http://www.holybible.or.kr/B_GAE/cgi/bibleftxt.php?VR={vr}&VL={vl}&CN={cn}&CV=99'
# 성경 이름을 기준으로 cn값을 늘려가며 값이 없을 떄 까지 iter한다.
res = requests.get(url)
if res.ok:
res.encoding = 'euc-kr'
soup = BeautifulSoup(res.text, 'html.parser')
content_list = soup.select('.tk4br .tk4l') # 태그네임은 변경될 가능성이 있다.
# 없는 cn을 조회할 경우 다음 vl로 넘어간다.
if len(content_list) == 0:
break
# 절과 말씀을 수집
contents = []
for num, i in enumerate(soup.select('.tk4br .tk4l')):
contents.append(str(num+1) + ' ' + i.get_text())
# 장, 내용 저장
bible[vr][name][cn] = contents
cn += 1 # 다음 장
else:
print(res.status_code)
위 코드를 통해 총 5개의 번역본(개역개정, 개역한글, 새번역, NIV, KJV)성경을 수집했으며 결과는 bible 변수에 담겼다. 그리고 주피터노트북에서 bible 변수를 실행한 내용을 ctrl+c 복사 후 bible.js에 ctrl+v했다. 물론 txt로든 json으로든 저장하는 코드를 구현할 수도 있겠지만 굳이 그럴 필요성을 느끼지 못했다. 복붙이 가능하면 그 방법이 제일 빠르다.
조회 서비스 개발(백엔드)
사이트는 express로 개발하고 동적으로 html을 랜더링할 예정이다. 폴더 트리는 아래와 같이 단순하다.
|-project
|- bible.js
|- index.js
|- bible_info.js
|- static
|- index.html
|- index.js사실상 서버 실행과 성경 조회를 위한 엔드포인트 하나만 필요한 상황이므로 백엔드의 index.js에 모두 다 넣었다.
/**
* Simple Bible Viewer
* 성경 말씀을 간단히 검색할 수 있도록 구현한 서비스 입니다.
* bible.js에 성경 내용을 그대로 보관하고 있습니다.
* bible_info.js에는 성경 책이름의 이니셜, 풀네임 정보가 array로 포함되어 있습니다.
* - initial = ['창', '출', '레'...]
* - fullname = ['창세기', '출애굽기', '레위기'...]
*/
const express = require('express');
const path = require('path');
const bible = require('./bible');
const { initial, fullname } = require('./bible_info');
const app = express();
const PORT = 3000;
app.use(express.json());
app.use(express.urlencoded({ extended: true }));
app.use('/static', express.static(path.join(__dirname, 'static')));
app.get('/', (req, res) => {
res.sendFile(path.join(__dirname, 'static', 'index.html'));
});
app.get('/search', async (req, res) => {
let { mode, compareMode, name, chapter } = req.query; // 번역본, 대조번역본, 성경이름, 장
// 책 이름 존재 여부 확인 (이니셜 또는 풀네임 검색 시 인덱스 넘버 획득, 없으면 -1 출력)
let nameIndex = initial.indexOf(name); // 이니셜로 먼저 검색
if (nameIndex === -1) { // 이니셜 목록에 없으면 풀네임 목록 확인
nameIndex = fullname.indexOf(name);
}
// request
res.send({
contents: searchBible(mode),
compareContents: searchBible(compareMode),
bookFullName: fullname[nameIndex],
});
// 성경 검색 func. : array | undefined
function searchBible(selectedMode) {
return bible?.[selectedMode]?.[initial[nameIndex]]?.[chapter];
}
});
app.listen(PORT, () => {
console.log(PORT, '포트에 접속하였습니다.');
});프론트 꾸미기
프론트는 form 태그의 select, option, input, button으로 꾸몄다.
번역번과 대조번역본 목록을 select 태그에 담고 책 이름과 '장' 입력은 input에 담아 '검색' 버튼으로 구성했으며 CSS 관련은 부트스트랩을 적용했다.
<body>
<div class="d-flex justify-content-center mt-3 mx-3">
<form class="row g-3" id="search-form">
<p class="fs-1 fw-bold" href="/">Simple Bible</p>
<div class="row">
<div class="col-5">
<select class="form-select" id="mode" aria-label="mode">
<option value="GAE">개역개정</option>
<option value="RHV">개역한글</option>
<option value="SAENEW">새번역</option>
<option value="NIV">NIV</option>
<option value="KJV">KJV</option>
</select>
</div>
<div class="col-5">
<select class="form-select" id="compare-mode" aria-label="compare-mode">
<option value="OFF">미사용</option>
<option value="GAE">개역개정</option>
<option value="RHV">개역한글</option>
<option value="SAENEW">새번역</option>
<option value="NIV">NIV</option>
<option value="KJV">KJV</option>
</select>
</div>
</div>
<div class="row">
<div class="col-5">
<input type="search" class="form-control" id="name" placeholder="창세기, 창" />
</div>
<div class="col-5">
<input type="search" class="form-control" id="chapter" placeholder="1" />
</div>
<div class="col-auto">
<button type="submit" class="btn btn-light mb-3">검색</button>
</div>
</div>
</form>
</div>
<div id="content-box" class="m-3"></div>
</body>그리고 버튼에 대한 이벤트리스너를 등록하여 select와 input 내용에 맞게 fetch하고, 받은 결과를 html에 적용했다.
const searchForm = document.querySelector('#search-form');
const contentBox = document.querySelector('#content-box');
searchForm.addEventListener('submit', async (event) => {
event.preventDefault();
const mode = document.querySelector('#mode').value;
const compareMode = document.querySelector('#compare-mode').value;
const name = document.querySelector('#name').value.trim();
const chapter = document.querySelector('#chapter').value.trim();
// Issue 1
const { modeName, compareModeName, contents, compareContents, fullname, result } = await search(
mode,
compareMode,
name,
chapter
);
if (!result) return (contentBox.innerHTML = '검색 결과가 없습니다.');
// Issue 2
// 대조 번역이 없을 경우
if (!compareModeName) {
contentBox.innerHTML = `<p class="fs-1 fw-bold mb-1">${fullname} ${chapter}장</p>`;
contentBox.innerHTML += `<p class="fs-5 fw-bold mb-5">${modeName}</p>`;
contentBox.innerHTML += contents.reduce(
(acc, verse) => acc + `<p class="fs-4 mb-4">${verse}</p>`,
''
);
// 대조 번역이 있을 경우
} else {
contentBox.innerHTML = `<p class="fs-1 fw-bold mb-1">${fullname} ${chapter}장</p>`;
contentBox.innerHTML += `<p class="fs-5 fw-bold mb-5">${modeName} - ${compareModeName}</p>`;
contentBox.innerHTML += contents.reduce(
(acc, verse, idx) =>
acc +
`<p class="fs-4 mb-1">${verse}</p>` +
`<p class="fs-8 mb-4">${compareContents[idx].slice(2)}</p>`, // slice verse number
''
);
}
});
async function search(mode, compareMode, name, chapter) {
const response = await fetch(
`/search?mode=${mode}&name=${name}&chapter=${chapter}&compareMode=${compareMode}`
);
const result = await response.json();
return result;
}위 코드가 정상적으로 작동하긴 하지만 주석에 적힌 Issue 1, 2 부분을 수정하고 싶었다.Issue 1의 경우 modeName과 compareModeName은 사실 프론트의 셀렉트 -> 옵션 태그에 이미 명시되어 있어 바로 가져올 수 있는 값인데 굳이 백엔드에서 제공해 줄 필요가 없다고 생각했다.Issue 2의 경우 코드 반복이 보인다. 또한 대조번역이 추가된다면 else if를 반복적으로 쓸 수 밖에 없는 구조를 갖는다.
// 코드 수정
searchForm.addEventListener('submit', async (event) => {
event.preventDefault();
// 필요한 Element 가져오기
const mode = document.querySelector('#mode');
const modeName = mode.options[mode.selectedIndex].text;
const compareMode = document.querySelector('#compare-mode');
const compareModeName = compareMode.options[compareMode.selectedIndex].text;
const bookName = document.querySelector('#name').value.trim();
const chapter = document.querySelector('#chapter').value.trim();
/** Issue 1:
* modeName과 compareModeName을 html 태그에서 획득했다.
*/
// 검색 요청
const { contents, compareContents, bookFullName } = await search(
mode.value,
compareMode.value,
bookName,
chapter
);
if (!contents) return (contentBox.innerHTML = '검색 결과가 없습니다.');
/** Issue 2:
* 쿼리셀렉터를 변수 지정하여 반복 사용을 피했다.
* 이름챕터 El, 모드 El, 콘텐츠 El 이렇게 세 부류의 태그로 구분하여 처리했다.
* 만약 대조 번역본을 2개 이상 조회가 가능하게 하려면 또 다시 코드 수정이 필요하다.
*/
// Content element 생성
const bookNameChapterEl = `<p class="fs-1 fw-bold mb-1">${bookFullName} ${chapter}장</p>`;
const modeNameEl =
compareMode.value === 'OFF'
? `<p class="fs-5 fw-bold mb-5">${modeName}</p>`
: `<p class="fs-5 fw-bold mb-5">${modeName} - ${compareModeName}</p>`;
const contentsEl = contents.reduce((acc, verse, idx) => {
firstModeContentsEl = `<p class="fs-4 mt-4 mb-1">${verse}</p>`;
secondModeContentsEl =
compareMode.value === 'OFF' ? '' : `<p class="fs-8 mb-4">${compareContents[idx].slice(2)}</p>`;
return acc + firstModeContentsEl + secondModeContentsEl;
}, '');
// Content element 추가
contentBox.innerHTML = bookNameChapterEl + modeNameEl + contentsEl;
});Issue 2에 대해서 태그 영역을 구분하여 볼 수 있도록 코드를 수정했지만 사실 깨끗하지 못한 건 여전하다. 더 깔끔하게 수정하기 위해서는 확장성을 고려하여 비교 번역본 N개를 담은 리스트 형태로 받아서 for문으로 태그를 생성하는게 더 좋을 것 같다. 하지만 그렇게 하기 위해서는 select 태그에서 다중 선택이 가능하도록 수정하는 것, 그 외 여러 군데 수정이 필요하므로 이쯤에서 마무리했다.
결과
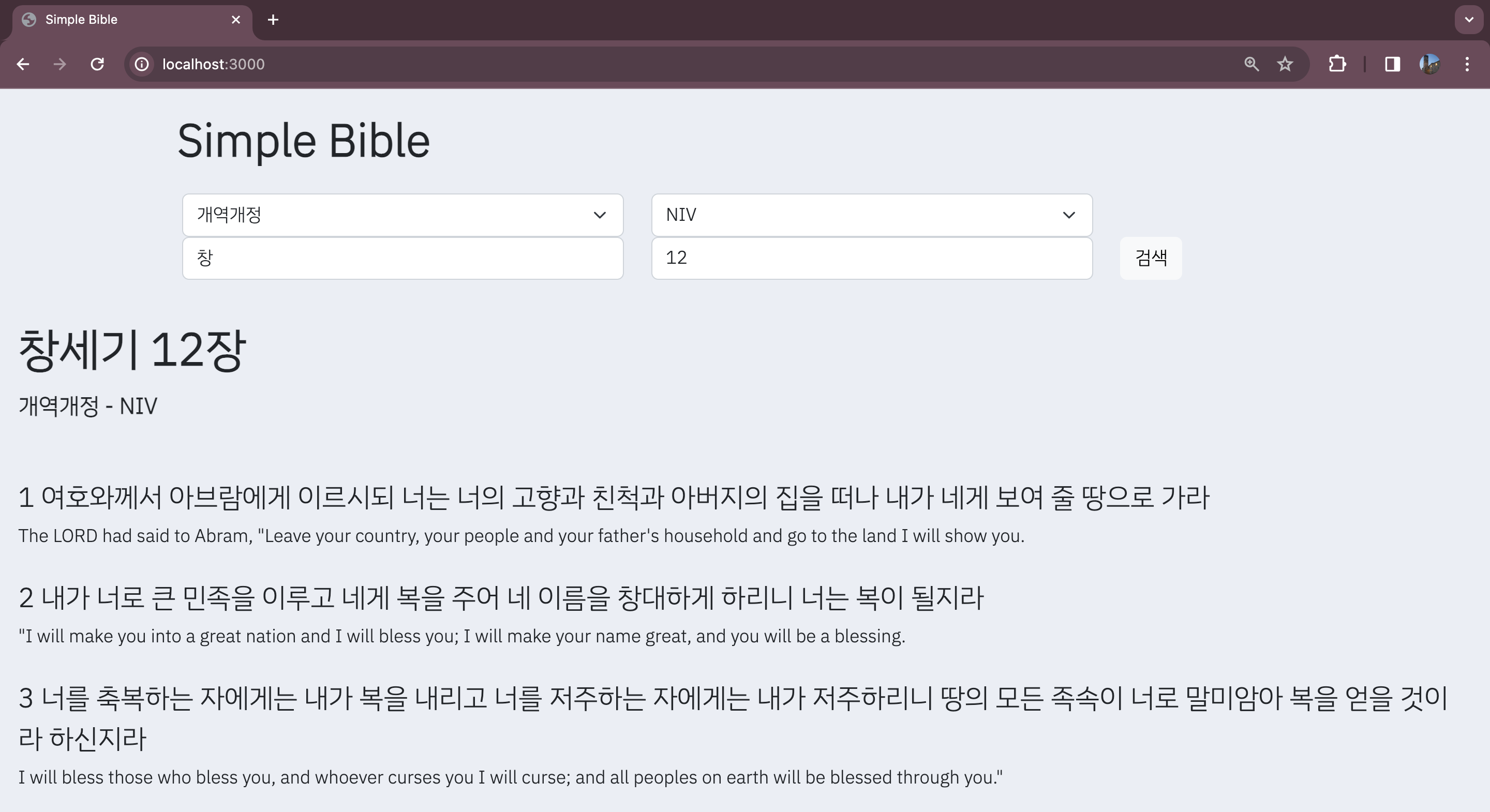
정리
현재는 클라이언트에서 fetch 함수를 통해 백엔드에 필요한 데이터를 가져오고, 받은 데이터를 기반으로 html을 수정하는 클라이언트 사이드 렌더링 방식을 취하고 있다. 이 방식은 성경 말씀을 검색할 때 서버에서 html을 완성해서 보내주는 서버사이드 렌더링보다 좀 더 빠른 검색 결과를 제공할 수 있다.
하지만 문제가 있다.
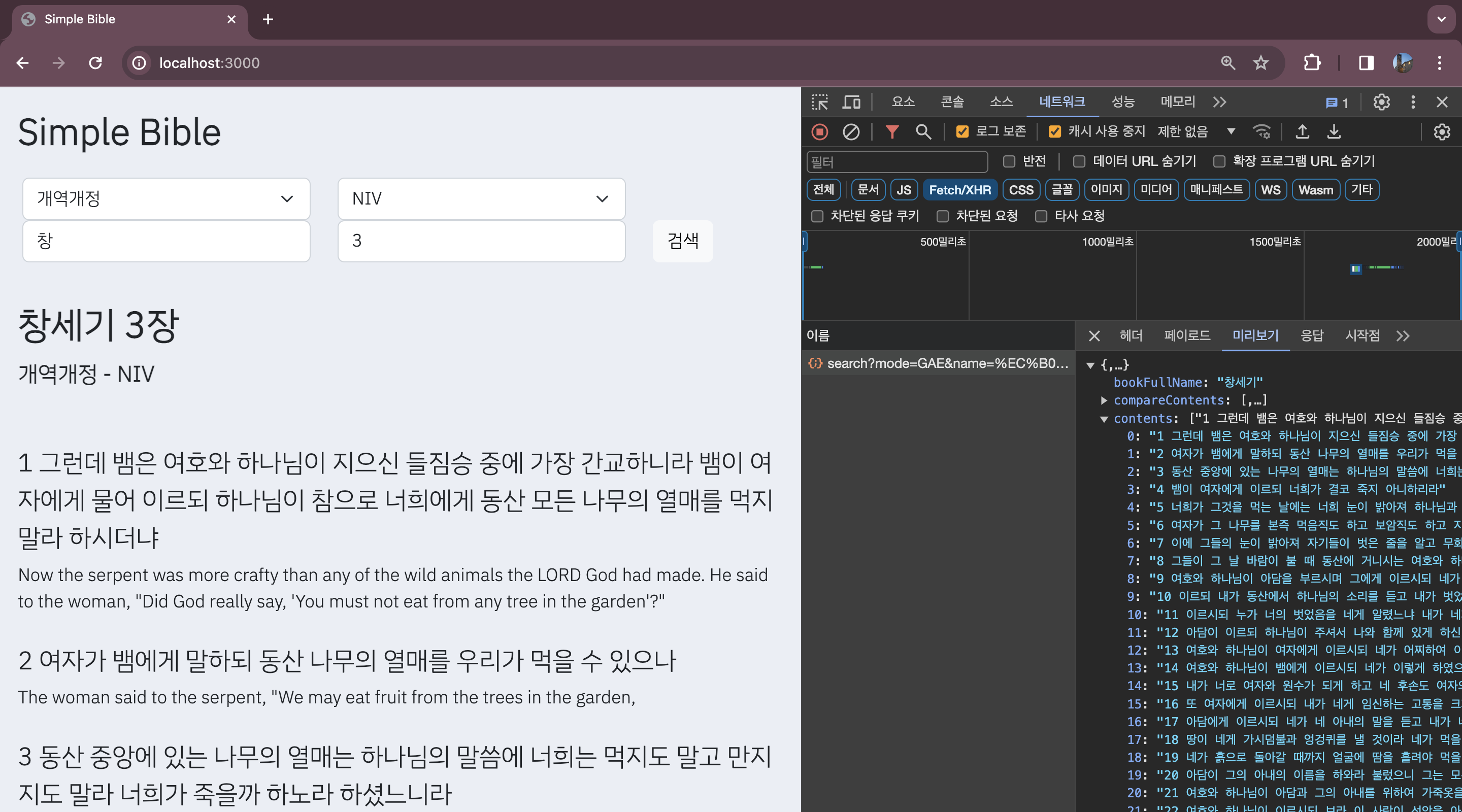
크롬 네트워크에 프론트에서 백엔드로 성경 말씀 요청을 보내는 엔드포인트가 헤더에 그대로 노출되기 때문에 크롤러는 위에서 언급했던 크롤링 2번 방식을 적용할 수 있다. 크롤러 입장에서는 땡큐지만 서버 입장에서는 html의 버튼클릭으로 데이터 요청을 받는 것 보다 훨씬 빠른 속도로 GET 요청을 받고 처리해 줘야한다. 클라우드 환경이라면 하나의 GET 요청이 다 돈이라는 것을 알 것이다. 게다가 심할 경우 서버 과부화를 일으킬 가능성도 존재하게 된다. (크롤러가 접근한다면 말이다.)
그래서 PUG나 EJS와 같은 View Engine을 써서 서버사이드 렌더링을 구현한다면 위와 같은 현상을 방지할 수 있을 것이다. 또한 구현한 김에 두 렌더링 방식에 대해 트래픽 테스트를 해보고 결과를 정리해 보는 것도 재밌을 것 같다.
'백엔드 개발자(node.js)가 되는 과정' 카테고리의 다른 글
| HTTP와 Kafka를 통한 MongoDB 도큐먼트 생성 비교 (부하테스트) (0) | 2024.01.31 |
|---|---|
| 카프카 컨테이너로 메시지 전송하기 - nest.js, python (0) | 2024.01.22 |
| 카프카로 메시지 전송하기 - Nest.js와 python (0) | 2024.01.05 |
| 백엔드 기술면접 회고 (2) Node.js 간단하게 파헤치기 (0) | 2023.12.27 |
| 백엔드 기술 면접 회고 (객체지향, 데이터베이스, 호이스팅과 스코프) (0) | 2023.12.22 |