728x90
SpanBERT
- SpanBERT는 텍스트 범위를 예측하는 질문-응답과 같은 Task에서 주로 사용된다.
- 기존 BERT의 MLM방식과 더불어 SBO방식을 함께 사전 학습에 활용한다.
token = [you, are expented, to, know, [MASK], [MASK], [MASK], [MASK], country]
SBO
- span boundry objective의 줄임말이다.
- 토큰의 연속 범위를 무작위로 MASK 처리한다.
- 기존 BERT 모델에서는 MASK 토큰의 예측을 위해 MASK의 representations을 활용했다면 SBO에서는 연속적인 MASK 토큰의 예측을 위해 나열된 MASK의 양쪽 경계에 있는 문자 토큰의 representation을 예측에 활용한다.
[you, are expented, to, **know,** [MASK], [MASK], [MASK], [MASK], country]
- 문제점
- 위 예시와 같이 첫번째 MASK를 예측하는데 쓰는 representation(know, country)과 두번째 MASK를 예측하는데 쓰는 representation이 동일하다.
- → 위와 같은 이유로 추가적으로 MASK 토큰의 위치 임베딩값을 사용한다.
- 정리하자면 첫번째 MASK 토큰을 예측할 경우 know, country의 representation과 더불어 첫번째 MASK 토큰의 위치 임베딩 벡터를 함께 활용한다.
SBO의 학습 방식
- 예측에 활용되는 데이터는 총 세 가지이다. → 양쪽 바운더리 토큰 표현 + 예측하고자 하는 MASK 토큰의 위치 임베딩
- 위 세 가지 데이터를 활용한 예측 결과를 아래 수식과 같이 표현할 수 있다.
- $z_i = f(R_{sos-1};R_{eos-1};P_{i-sos+1})$
- $f(\centerdot)$은 2개의 피드포워드와 GeLU 함수로 구성된다.$h_1 = LayerNorm(GeLU(W_1h_0))$
- $z_i = LayerNorm(GeLU(W_2h_1))$
- $h_0 = [R_{s-1};R_{e-1};P_{i-s+1}]$
- 각각의 MASK 예측 결과는 vocab에 담긴 모든 토큰을 대상으로 한 확률값으로 출력되어 argmax로 출력한다.
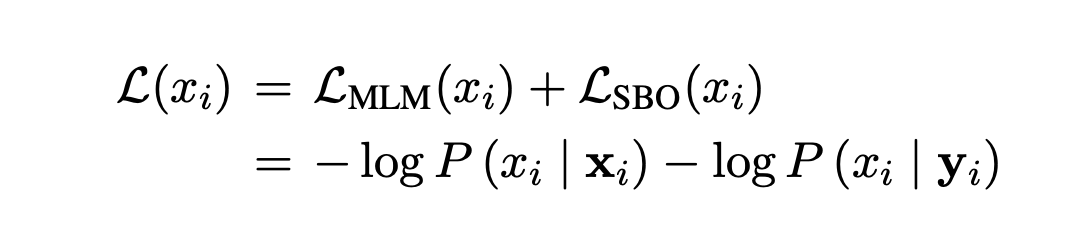
- Loss Function은 MLM과 SBO의 cross-entropy한 각각의 결과 합산하여 최소화 하는 방식을 취하고 있다.
728x90
728x90
'데이터사이언스 이론 공부' 카테고리의 다른 글
| GPT3 모델의 대한 간략한 정리 (0) | 2023.01.09 |
|---|---|
| BERT의 파생모델 [DistilBERT] (0) | 2022.12.30 |
| BERT의 파생모델 [ELECTRA] (0) | 2022.12.26 |
| BERT의 파생 모델 [RoBERTa] 특징 (0) | 2022.12.22 |
| BERT의 파생 모델 [ALBERT] (1) | 2022.12.20 |