728x90
GPT3 왜 나왔는가?
- 기존 PLM (pre-trained model) 은 사전 학습 이후 fine-tuning해서 사용.
- Downstream Task에 수천~수만 건이 데이터가 필요함
- fine-tuning은 기존의 지니고 있던 일반화 성능을 저하시킨다.
- 실제 성능보다 SQuAD같은 특정 벤치마크에서 과대평가될 수 있다. (이것도 성능의 일반화 문제)
- 각 Task마다 fine-tuning된 모델이 필요하게 된다. (모델의 기능이 복합적이지 못함)
GPT3의 특징
- Few-shot learning이 가능 (매우 적은 수의 데이터로도 downstream task 학습이 가능함을 의미)
- GPT 모델의 작동 방식을 살펴보면 엄연히 말해서 학습한다고 말하기도 애매함
- 추가적인 파라미터 업데이트 없이 다양한 task 수행 가능
- downstream task별로 모델을 만들 필요가 없음
- 파라미터 수가 1750억 개
In-Context Learning

- Feed-Foward만으로 학습을 수행
- Task description과 몇 개의 Few-shot examples를 던져주고서(이를 합쳐서 prompt라 부른다.) 그 다음에 Query를 던져주면 앞의 examples를 바탕으로 답을 리턴(Generate)해주는 원리
→ Prompt (또는 Context)를 입력하면 그 뒤 Query값에 대한 답을 생성한다.
→ context examples에서 발견한 연관성을 보고서 그 뒤 문장을 likelihood에 근거하여 단어를 생성한다.
- Task description과 몇 개의 Few-shot examples를 던져주고서(이를 합쳐서 prompt라 부른다.) 그 다음에 Query를 던져주면 앞의 examples를 바탕으로 답을 리턴(Generate)해주는 원리
- Google T5 논문에서 제안한 Text-to-Text 방식의 사전 학습을 적용함
→ NLU Task의 Classification 문제도 NLG 방식처럼 정답을 토큰으로 출력하게 하면 된다는 내용이다. (기존 BERT와 같은 Auto-encoding모델의 방식은 CLS 토큰을 기반으로 fine-tuning을 통해 분류 Task를 수행하도록 했다.)
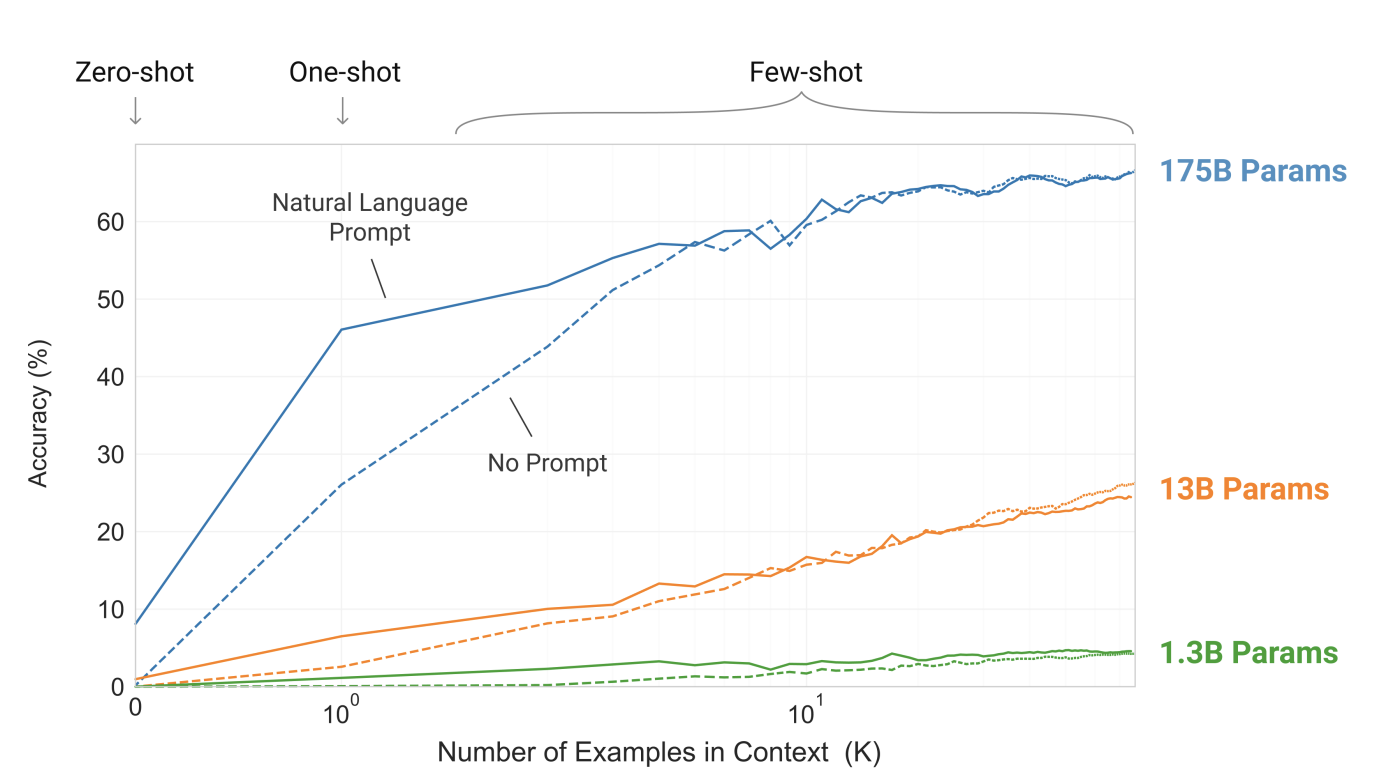
- 모델의 크기를 키운 뒤 주어진 context 몇 개에 기반하여 다음 문장을 완성하도록 했더니 성능이 향상하는 것을 발견
- 파라미터의 갯수를 늘렸을 경우 One-shot에서 성능이 꽤 높은 것을 확인할 수 있으며 few-shot의 개수가 늘어날수록 성능이 향상하는 것도 확인할 수 있다.
방법
- 트랜스포머 디코더만 사용해서 사전 학습을 진행
- 문장의 단어를 넣어서 다음 단어를 맞히게 하는 기본적인 Language Modeling Task 진행
- GTP2에 비해 파라미터 갯수를 무지하게 늘린 후 무지하게 학습을 시켰다.
→ 트랜스포머 디코더만을 가져와 모델의 크기를 대폭 향상시키고서 데이터를 많이 넣었다.
전처리

- Byte BPE 사용
- 'Common Crawl' 데이터를 주로 사용
- 여러 데이터를 사용했지만 데이터의 품질에 따른 가중치를 두어 학습시켰다.
→ 300억 개의 토큰을 학습하는 동안 위키피디아 데이터를 3.4번 보도록 설정했다.
평가

- GPT가 충분히 파라미터가 많을 경우 SuperGLUE Task에서 Fine-tuned BERT-Large에 필적하는 성능을 보인 것을 확인할 수 있다. GPT는 Few-shot learning만으로 성능을 넘어선 것이다.
- 해당 논문에서는 Few-shot example 최대 32개로 설정하여 테스트한 것을 볼 수 있으며 Few-shot example의 수가 늘어날수록 성능이 향상되는 것도 확인할 수 있다.
한계점
- Hallucination issue
→ GPT3의 문장 생성 능력은 유창하지만 실 정보가 팩트가 아닌 케이스가 다수 발견된다. - Auto-regressive 특성 상 bi-directional Task에서의 성능이 떨어진다.
- 단어의 개념에 대해서 이해를 했다고 보기 어렵다.
→ 글을 많이 봐서 다른 글, 문자와의 관계, 빈도에 대한 정도를 잘 알고 있는 수준이며, 문제를 푸는 방식 또한 likelihood이므로 단어 자체가 지닌 의미를 이해하지 못한다. - 175B의 파라미터를 지닌 만큼 Few-shot learning을 진행할 수 밖에 없다.
→ 입력 길이의 제한이 생길 수 밖에 없다. 왜냐하면 GPT3가 실제 입력 길이에 제한을 두지 않더라도, 입력 문장과 그에 따른 175B의 weight를 메모리에 들고서 연산을 진행해야 하므로 explode 가능성이 높아진다. 이를 방지하기 위해 GPT3는 초반에 입력된 정보를 버리게 될 것이고, 이는 성능 저하를 일으킬 수 있다.
Prompt Engineering
- 사용자가 직접 Prompt를 구성해야 하는데 이 구성을 어떻게 하느냐에 따라 성능의 폭이 넓어진다.(성능이 들쑥날쑥한다.)
→ 다양한 표현법이지만 하고자 하는 말은 하나인 prompt에 대한 고도의 처리 능력이 필요하다.)
Few-shot learning으로 인한 여러 Bias가 생긴다.
→ 기본적으로 Few-shot examples의 절대량이 적기 때문에 발생하는 문제
- Classification Task에서 입력값 중 더 자주 등장한 class 결과로 예측이 편향될 수 있다.
- 최근에 나온 example에 대한 class로 예측이 편향될 수 있다.
- Text-to-Text 방식은 정답이 되는 class 이름도 사전 학습된 데이터 이므로 class의 이름 자체가 다른 class명에 비해 학습량이 많았다면 이 또한 편향을 부를 수 있다.
어떻게 Bias를 다룰 것인가?
- RoBERTa의 CLS 토큰을 활용한 유사 representation을 선정하여 in-context elarning example로 활용한다.
→ 유사 문장의 개수를 체크하여 학습 데이터를 균등하게 맞춰 Bias를 방지하겠다는 의미 - bias를 calibration해서 최소화 하는 방법을 제안
→ 예를 들어 긍,부정 classification 문제에서 긍정도 부정도 아닌 중립의 정답을 내놓아야 하는 example을 제시했을 떄 실제로 중립값이 나오도록 Linear+softmax 레이어를 추가하여 조정하는 방식
728x90
728x90
'데이터사이언스 이론 공부' 카테고리의 다른 글
| DNN(Deep Neural Network) 구현하기 with numpy(2) - Initialize (1) | 2023.01.19 |
|---|---|
| DNN(Deep Neural Network) 구현하기 with numpy(1) - Preprocess (0) | 2023.01.16 |
| BERT의 파생모델 [DistilBERT] (0) | 2022.12.30 |
| BERT의 파생모델 [SpanBERT] (0) | 2022.12.29 |
| BERT의 파생모델 [ELECTRA] (0) | 2022.12.26 |