728x90
Hyper-Parameter optimization
- 랜덤포레스트 모델의 하이퍼 파라미터 튜닝(optimization)에 대해서 알아본다.
로그 데이터 저장
- 로그데이터를 log파일로 남기는 함수를 작성했다. 이를 활용하면 편리하게 결과를 하나의 로그파일에 적재할 수 있다.
import logging
def get_logger(name, dir_, stream=False):
"""log 데이터 파일 저장
Args:
name(str): 로그 이름 지정
dir_(str): 로그 파일을 저장할 경로 지정
stream(bool): 콘솔에 로그를 남길지에 대한 유무
Returns: logging.RootLogger
"""
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(name)
logger.setLevel(logging.INFO) # logging all levels
logger.handlers.clear() # 중복 입력 방지
formatter = logging.Formatter('%(asctime)s | %(name)s | %(levelname)s | %(message)s')
stream_handler = logging.StreamHandler()
file_handler = logging.FileHandler(os.path.join(dir_, f'{name}.log'))
stream_handler.setFormatter(formatter)
file_handler.setFormatter(formatter)
if stream:
logger.addHandler(stream_handler)
logger.addHandler(file_handler)
return logger
GridSearch CV 구현
개념만 가지고 직접 구현해보자
- 파라미터 적용 후보값을 지정해주면 해당 값의 모든 조합을 나열한다.
- 나열된 조합을 모델에 적용 후 K-Fold CV를 통해 학습 및 평가한다.
- 모든 조합 중 성능이 가장 좋은 조합을 확인한다.
먼저 Product 함수를 활용하면 각 리스트 간 조합을 편리하게 적용할 수 있다.
param_grid = {
'max_depth': [50, 80, 100],
'n_estimators': [65, 70, 75]
}
from itertools import product
# product 함수는 여러 튜플 입력 시 튜플 내 모든 조합을 인풋 순서에 따라 순차적으로 출력해준다.
# ex) (1, 2, 3), (4, 5, 6) -> (1, 4), (1, 5), (1, 6), (2, 4), ...
names = param_grid.keys()
value_cand = param_grid.values()
for value in product(*value_cand):
params = {key:value for key, value in zip(names, value)}
print(params)
>>>
{'max_depth': 50, 'n_estimators': 65}
{'max_depth': 50, 'n_estimators': 70}
{'max_depth': 50, 'n_estimators': 75}
{'max_depth': 80, 'n_estimators': 65}
{'max_depth': 80, 'n_estimators': 70}
{'max_depth': 80, 'n_estimators': 75}
{'max_depth': 100, 'n_estimators': 65}
{'max_depth': 100, 'n_estimators': 70}
{'max_depth': 100, 'n_estimators': 75}
- 위 함수를 기반으로 기능 구현하기
from sklearn.model_selection import KFold
from sklearn.metrics import f1_score
from sklearn.ensemble import RandomForestClassifier
from datetime import datetime, timezone, timedelta
from tqdm.notebook import tqdm
from itertools import product
import os
# grid search 함수에 필요한 파라미터 설정
config = {
'recorder_dir': './',
'model': RandomForestClassifier(),
'param_grid': {
'max_depth': [50, 80, 100],
'n_estimators': [65, 70, 75]
},
'metric_info': [f1_score, {'average': 'macro'}],
'cv': 5
}
def grid_search_cv(X, y, model, param_grid, cv, metric_info, recorder_dir):
"""Grid Search CV를 실행합니다.
Args:
X(array): X data
y(array): label data
model(func): 모델 선택
param_grid(dict): GridSearch에 적용할 파라미터 범위
{'파라미터명': [값1, 값2, ...]}
cv(int): cross_validation 개수
metric_info(list): 평가지표 및 평가지표의 파라미터 설정
['평가지표함수', {'파라미터1': '값'...}]
recorder_dir(str): log파일 저장 위치
Returns:
best_score(float)
best_params(dict)
"""
# train serial (튜닝 시작 시간을 따로 기록해둔다.)
kst = timezone(timedelta(hours=9)) # 우리나라는 UTC 기준으로 9시간 빠름
train_serial = datetime.now(tz=kst).strftime("%Y%m%d_%H%M%S")
# get logger
logger = get_logger(name=f'train_GSCV', dir_=recorder_dir, stream=False)
logger.info(f"-----GRID SEARCH START-----")
logger.info(f"Start Date: {train_serial}")
logger.info(f"Configure {config}\n")
score_list = []
params_list = []
names = param_grid.keys() # parameter names
value_cand = param_grid.values() # value candidate
# itertools의 product 함수는 여러 튜플 입력 시 튜플 내 모든 조합을 인풋 순서에 따라 순차적으로 출력해준다.
# ex) (1, 2, 3), (4, 5, 6) -> (1, 4), (1, 5), (1, 6), (2, 4), ...
# 모든 조합의 수
candidates = 1
for cand in value_cand:
candidates *= len(cand)
# log information
logger.info(f"Fitting {cv} folds for each of {candidates} candidates, totalling {candidates*cv} fits")
for i, value in zip(tqdm(range(candidates)), product(*value_cand)): # asterisk를 붙여야 리스트를 인식한다.
params = {key:value for key, value in zip(names, value)}
# k-fold CV
avg_score = 0
k_fold = KFold(n_splits=cv, shuffle=False)
for train_idx, test_idx in k_fold.split(X):
train_x, train_y = X[train_idx, :], y[train_idx]
test_x, test_y = X[test_idx, :], y[test_idx]
# train, predict
model.set_params(**params).fit(train_x, train_y)
pred = model.predict(test_x)
# metric
metric, metric_params = metric_info
score = metric(test_y, pred, **metric_params)
# update avg_score
avg_score += score / cv
# collect
score_list.append(avg_score)
params_list.append(params)
logger.info(f"*****CANDIDATE_NO.{str(i+1).zfill(3)} RESULT*****")
logger.info(f"Parameters: {params}")
logger.info(f"{metric.__name__}: {avg_score}")
# Final Result
best_score = max(score_list)
best_params = params_list[score_list.index(best_score)]
logger.info(f"*****ITERATION END*****")
logger.info(f"Best Score: {best_score} Best Params: {params_list[score_list.index(best_score)]}")
logger.info(f"-----GRID SEARCH END-----\n")
return best_score, best_params
# Run
best_score, best_params = grid_search_cv(train_x, train_y, **config)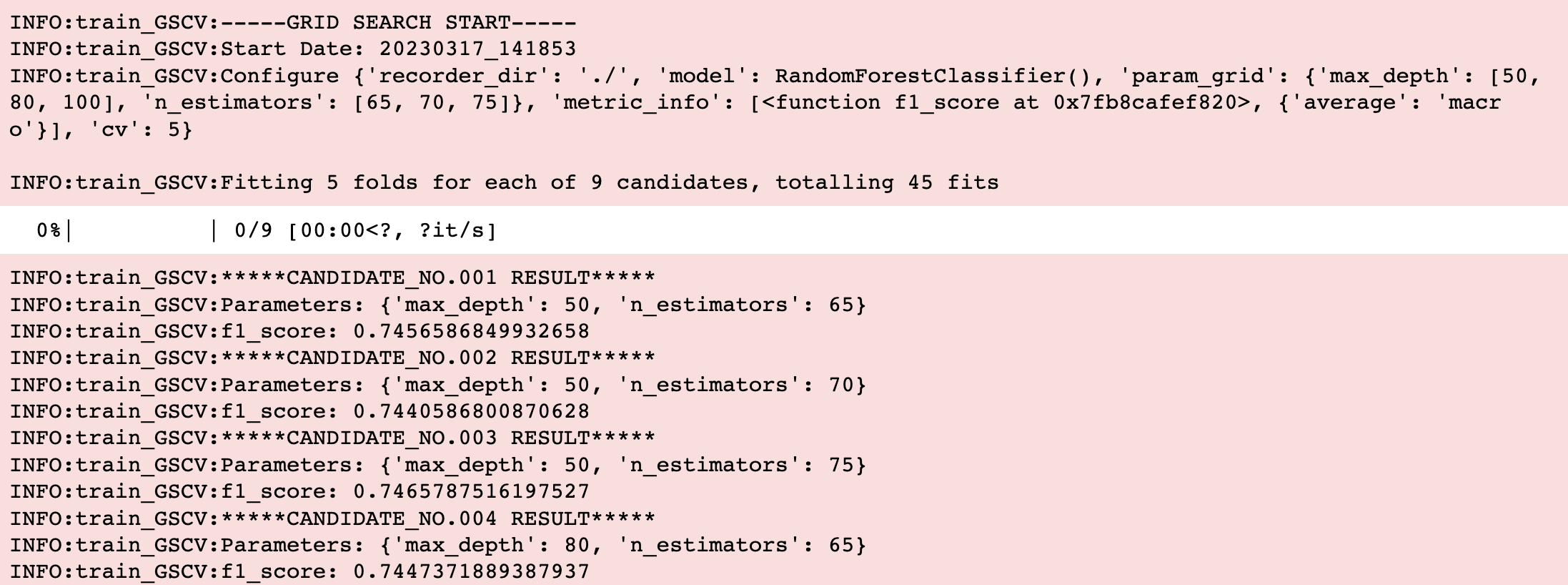
RandomSearch CV 구현
개념만 가지고 직접 구현해보자
- 수치형 데이터를 요구하는 각 파라미터의 최소, 최대값을 정해주면 해당 범위 내에서 랜덤한 값을 샘플링하여 사용하는 방식이다. string 타입은 목록 중에서 랜덤선정한다.
- 파라미터값을 선정 후 K-Fold CV로 한 번의 iteration에 K번 만큼 평가한 후 평균 score를 채택한다.
- 랜덤 서치는 지정한 횟수(iteration)만큼 반복한다.
from sklearn.model_selection import KFold
from sklearn.metrics import f1_score
from sklearn.ensemble import RandomForestClassifier
from datetime import datetime, timezone, timedelta
from tqdm.notebook import tqdm
import os
# random search 함수에 필요한 파라미터 설정
config = {
'recorder_dir': './',
'model': RandomForestClassifier(),
'param_grid': {
'max_depth': ([100, 105], 'int'),
'n_estimators': ([70, 75], 'int'),
'min_samples_split': ([5, 7], 'int'),
'min_samples_leaf': ([1, 2], 'int'),
'criterion': (['gini', 'entropy'], 'str')
},
'metric_info': [f1_score, {'average': 'macro'}],
'num_iter': 10,
'cv': 5
}
def random_search_cv(X, y, num_iter, model, param_grid, cv, metric_info, recorder_dir):
"""Random Search CV를 실행합니다.
Args:
X(array): X data
y(array): label data
num_iter(int): iteration 횟수 지정
model(func): 모델 선택
param_grid(dict): RandomSearch에 적용할 파라미터 범위
{'파라미터명': ([최소값: 최대값], 'type')...}
cv(int): cross_validation 개수
metric_info(list): 평가지표 및 평가지표의 파라미터 설정
['평가지표함수', {'파라미터1': '값'...}]
recorder_dir(str): log파일 저장 위치
Returns:
best_score(float)
best_params(defaultdict)
"""
# train serial (튜닝 시작 시간을 따로 기록해둔다.)
kst = timezone(timedelta(hours=9)) # 우리나라는 UTC 기준으로 9시간 빠름
train_serial = datetime.now(tz=kst).strftime("%Y%m%d_%H%M%S")
# get logger
logger = get_logger(name=f'train', dir_=recorder_dir, stream=False)
logger.info(f"-----RANDOM SEARCH START-----")
logger.info(f"Start Date: {train_serial}")
logger.info(f"Configure {config}\n")
score_list = []
params_list = []
for i in tqdm(range(num_iter), leave=False):
# hyper-parameter random sampling
params = dict()
for name, value_info in param_grid.items():
if len(value_info[0]) == 1:
params[name] = value_info[0][0]
elif value_info[1] == 'int':
params[name] = np.random.randint(min(value_info[0]), max(value_info[0])+1)
elif value_info[1] == 'float':
params[name] = np.random.uniform(min(value_info[0]), max(value_info[0]))
elif value_info[1] == 'str':
params[name] = np.random.choice(value_info[0])
# k-fold CV
avg_score = 0
k_fold = KFold(n_splits=cv, shuffle=False)
for train_idx, test_idx in k_fold.split(X):
train_x, train_y = X[train_idx, :], y[train_idx]
test_x, test_y = X[test_idx, :], y[test_idx]
# train, predict
model.set_params(**params).fit(train_x, train_y)
pred = model.predict(test_x)
# metric
metric, metric_params = metric_info
score = metric(test_y, pred, **metric_params)
# update avg_score
avg_score += score / 5
# collect
score_list.append(avg_score)
params_list.append(params)
logger.info(f"*****ITERATION_{str(i+1).zfill(3)} RESULT*****")
logger.info(f"Parameters: {params}")
logger.info(f"{metric.__name__}: {avg_score}")
# Final Result
best_score = max(score_list)
best_params = params_list[score_list.index(best_score)]
logger.info(f"*****ITERATION END*****")
logger.info(f"Best Score: {best_score} Best Params: {params_list[score_list.index(best_score)]}")
logger.info(f"-----RANDOM SEARCH END-----\n")
return best_score, best_params
# Run
random_search_cv(X, y, **config)
- 위와같이 Iteration이 도는 동안 기록을 눈으로 확인함과 동시에 기록을 남길 수 있다.
- 하이퍼 파라미터 범위를 수정 후 재가동 한다해도 ‘train.log’ 파일에 지속적으로 적재된다.
# read log file
with open("train.log", "r", encoding='utf-8') as f:
for line in f:
print(line, end="")
>>>
2023-03-15 18:17:06,828 | train | INFO | -----RANDOM SEARCH START-----
2023-03-15 18:17:06,865 | train | INFO | Start Date: 20230315_181706
2023-03-15 18:17:06,877 | train | INFO | Configure {'recorder_dir': './', 'model': RandomForestClassifier(), 'param_grid': {'max_depth': ([100, 105], 'int'), 'n_estimators': ([70, 75], 'int'), 'min_samples_split': ([5, 7], 'int'), 'min_samples_leaf': ([1, 2], 'int'), 'criterion': (['gini', 'entropy'], 'str')}, 'metric_info': [<function f1_score at 0x7fd1e30489d0>, {'average': 'macro'}], 'num_iter': 10, 'cv': 5}
2023-03-15 18:17:12,309 | train | INFO | *****ITERATION_001 RESULT*****
2023-03-15 18:17:12,311 | train | INFO | Parameters: defaultdict(None, {'max_depth': 100, 'n_estimators': 72, 'min_samples_split': 7, 'min_samples_leaf': 1, 'criterion': 'entropy'})
2023-03-15 18:17:12,311 | train | INFO | f1_score: 0.7537978944002951
2023-03-15 18:17:17,137 | train | INFO | *****ITERATION_002 RESULT*****
2023-03-15 18:17:17,138 | train | INFO | Parameters: defaultdict(None, {'max_depth': 100, 'n_estimators': 73, 'min_samples_split': 5, 'min_samples_leaf': 2, 'criterion': 'entropy'})
2023-03-15 18:17:17,139 | train | INFO | f1_score: 0.7512725097026567
...
- 당연하겠지만 with open으로도 log를 확인할 수 있다.
728x90
728x90
'데이터사이언스 이론 공부' 카테고리의 다른 글
| ERC - CoMPM 모델 논문 구현 (0) | 2023.01.26 |
|---|---|
| DNN(Deep Neural Network) 구현하기 with numpy(2) - Initialize (1) | 2023.01.19 |
| DNN(Deep Neural Network) 구현하기 with numpy(1) - Preprocess (0) | 2023.01.16 |
| GPT3 모델의 대한 간략한 정리 (0) | 2023.01.09 |
| BERT의 파생모델 [DistilBERT] (0) | 2022.12.30 |